The New Version of Easegress
MegaEase is happy to announce a new version of Easegress, 2.0.0, this is the second major release, including a significant enhancement to the traffic orchestration feature, protocol-independent pipeline, and many other improvements.
Why Easegress
When deploying web services, we often use a traffic gateway as a reverse proxy, and there are many excellent gateway products in the industry, like Nginx. However, these products were born before cloud-native, therefore, they are facing various problems after entering the cloud-native era, including
- Lack of high availability deployment options;
- Lack of traffic coloring, dynamic orchestration;
- Lack of monitoring, service discovery, etc.
On the other hand, the intrusion of various business logic also requires the system to be easily extended. Nginx uses C and Lua for this, which is not good enough, because C is too obscure and error-prone, and Lua is not expressive enough.
MegaEase believes that the traffic gateway in the cloud-native era cannot be just a reverse proxy, but also support dynamic traffic orchestration and scheduling. In addition, it must be highly extensible to deal with various business logic intrusions.
Based on the above points, MegaEase developed the new generation of traffic gateway products - Easegress. This product is completely built on cloud-native technologies, with native support for high availability, dynamic traffic orchestration, observability, and scalability. Especially for extensibility, Easegress has relevant designs in several aspects:
First of all, in terms of the choice of development language, after comparing the mainstream static languages such as C, C++, Java, Rust, Go, etc., we believe that Go has the advantages of both ease of use and excellent performance. Therefore, Easegress finally choose Go as the development language. But no matter which language is used, source-level extensions inevitably limit users to a specific language and involve recompilation, redeployment, restarting, and service interruptions.
The second way to provide extensibility is FaaS, it does not limit the user’s development language, and it also has good scalability. The disadvantage is that it relies heavily on external dependencies such as Kubernetes, which brings the complexity of the operation. (Easegress supports Knative).
The third way is embedding an interpreter. At first, we put our focus on Lua, a language that is designed for embedding into other programs, but after a detailed evaluation, we believe that Lua has two weak points. One is that it is not expressive enough and is not suitable for writing complex business logic; the other is that it is not popular enough and it is hard to find programmers with relevant experience. Therefore, we decided to embed WebAssembly, mainly based on two considerations: one is the nearly native performance; the other is it is not restricting the user’s development language, users can use their favorite or familiar language to develop business logic.
Why Easegress 2.0
The above improvements compared to traditional traffic gateways have been implemented in Easegress v1.x already. However, with the increase of users, new users have brought new requirements and new problems, including
Easegress originated from a real user project, so it has practically solved users’ problems since its birth, but this also made its initial design too close to the specific scene, and lack forward-looking. We know that Pipeline is the core component of Easegress for traffic orchestration, but since the initial user only asked us to support HTTP, the pipeline implementation is tightly bound to HTTP. So, when we want to support MQTT, TCP, and other protocols, we have to implement new pipelines for these protocols. These pipelines are similar, and multiple different implementations are neither conducive to use nor maintenance. Therefore, we need a protocol-independent pipeline implementation for all protocols.
Easegress supports API orchestration, and we have developed filters for complex orchestration, including API Aggregator, Request Adaptor, Response Adaptor, etc. But these filters are actually in a state of fighting by themselves, and cannot be combined to achieve the result of 1+1>2. For example, we can read a blog’s RSS feed through Easegress, and we can send a message to Slack through Easegress, but we can’t read the RSS feed, and then send the article list to Slack.
There is no clear distinction between control logic and business logic. In general, business logic handles the creation, deletion, and modification of data, while control logic determines the order in which various operations are performed. Although the division of the two is not absolute, in the pipeline, we can think that business logic is to process requests & responses, and the control logic is the orchestration and resilience processing of the filters. Therefore, filters in Easegress should focus on business logic. But in Easegress v1.x, control logic such as retry and circuit breaker are implemented through filters, which forces the Pipeline to use a complex chain of responsibility pattern to call filters, resulting in incomprehensible calling logic, and misunderstandings in certain scenarios.
Major Improvements
Easegress v2.0 was designed to avoid the above problems.
Multi-protocol support: In order for Easegress’ pipeline to support multiple protocols, we need to abstract the protocols that the pipeline handles. Generally speaking, a protocol entity contains headers and a body. The headers are basically key-value pairs for protocol control, and the body is business content. So, we need to abstract the protocol entities into contextual objects.
Decoupling of control logic and business logic: Some resilience(circuit breaker, timeout, retry, etc.) related control logics are implemented as filters in Easegress v1.x, we think this is a mistake. These logics are actually used to protect the back-end service, the implementation in v1.x results in a mix of the control logic and the business logic, which makes things messy. In v2.0, they are embedded onto the Proxy filter, and the whole processing logic is now clean and clear.
Powerful and easy-to-use API orchestration: This is a key improvement, a gateway is to proxy, orchestrate and combine various APIs, so we need a more powerful, easy-to-use, and code-free DSL for API orchestration.
Next, let’s use an example to demonstrate the API orchestration feature of Easegress v2.0.
API Orchestration
In this example, we will use Easegress (please follow this document to install Easegress v2.0 in advance) to implement a Telegram bot that receives a message from Telegram, calls AWS’s translation API to translate it into the target language, then calls AWS’s TTS engine Polly to convert the translation to speech and returns it to Telegram. That is, to implement the functions in the following figure:
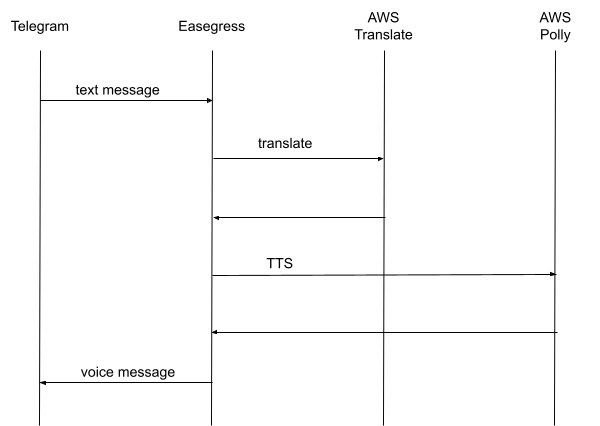
The entire process involves three API calls (translation, TTS, and messaging to Telegram), and the later calls depend on the results of the earlier calls.
The requirement is not complex, but like we mentioned earlier about reading RSS and sending it to Slack, Easegress v1.x cannot directly implement this requirement, and in fact, other traditional gateways such as Nginx cannot implement it directly either. All a traditional gateway can do is act as a reverse proxy, forwarding client requests to back-end services. This process involves coding, service deployment, and configuration of the gateway, which is not technically difficult, but complicated.
In Easegress v2.0, we can do this directly through API orchestration, without writing any code or deploying a service. Let’s look at the specific approach.
First, we need to create a bot and set up a WebHook according to Telegram’s documentation. This part is not very relevant to Easegress, so we will skip the details (in the following example, the bot name is EaseTranslateBot).
We then use a RequestBuilder, a RequestAdaptor, and a Proxy to translate the text message from Telegram, RequestAdaptor signs the request according to AWS requirements, and the Proxy sends the request out and receives the translation results. The RequestBuilder configuration is somewhat complex due to the need to comply with AWS requirements, which is necessary, and the complexity of implementing the same functionality in other ways would be similar.
filters:
- kind: RequestBuilder
name: requestBuilderTranslate
template: |
{{$msg := or .requests.DEFAULT.JSONBody.message .requests.DEFAULT.JSONBody.channel_post}}
{{if contains "@easetranslatebot" (lower $msg.text)}}
{{$lang := or (trim (replace "@easetranslatebot" "" (lower $msg.text))) "chinese"}}
{{$lang = index .data.PIPELINE (lower $lang)}}
method: POST
url: https://translate.us-east-2.amazonaws.com/TranslateText
headers:
"Content-Type": ["application/x-amz-json-1.1"]
"X-Amz-Target": ["AWSShineFrontendService_20170701.TranslateText"]
body: |
{
"SourceLanguageCode": "auto",
"TargetLanguageCode": "{{$lang.code}}",
"Text": "{{$msg.reply_to_message.text | jsonEscape}}"
}
{{end}}
- name: requestAdaptorTranslate
kind: RequestAdaptor
sign:
apiProvider: aws4
# Please use your own access key & secret
accessKeyId: AKXXXXXXXXXXXXXXXXXX
accessKeySecret: XYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY
scopes: ["us-east-2", "translate"]
- name: proxyTranslate
kind: Proxy
pools:
- servers:
- url: https://translate.us-east-2.amazonaws.com
Note that in the template of the RequestBuilder, in addition to use the information in the original request, we also use the user data set on the pipeline to convert the target language from a user-friendly form to the language code of the AWS translation (e.g., converting the target language from Chinese to zh). The user data is set up on the pipeline using the following format (the speech engine used for each language is also set up for converting text to speech).
data:
chinese:
code: zh
voice: Zhiyu
english:
code: en
voice: Joanna
...
Once the translation is complete, we need to convert the translated text to speech, again using a RequestBuilder, a RequestAdaptor, and a Proxy.
filters:
...
- kind: RequestBuilder
name: requestBuilderPolly
template: |
{{$msg := or .requests.DEFAULT.JSONBody.message .requests.DEFAULT.JSONBody.channel_post}}
{{$lang := or (trim (replace "@easetranslatebot" "" (lower $msg.text))) "chinese"}}
{{$lang = index .data.PIPELINE (lower $lang)}}
method: POST
url: https://polly.us-east-2.amazonaws.com/v1/speech
headers:
"Content-Type": ["application/json"]
body: |
{
"Engine": "standard",
"OutputFormat": "ogg_vorbis",
"Text": "{{.responses.translate.JSONBody.TranslatedText | jsonEscape}}",
"VoiceId": "{{$lang.voice}}"
}
- name: requestAdaptorPolly
kind: RequestAdaptor
sign:
apiProvider: aws4
# Please use your own access key & secret
accessKeyId: AKXXXXXXXXXXXXXXXXXX
accessKeySecret: XYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY
scopes: ["us-east-2", "polly"]
- name: proxyPolly
kind: Proxy
pools:
- servers:
- url: https://polly.us-east-2.amazonaws.com
After that, we send the translation results to Telegram, which does not require a signature, so this step uses one less RequestAdaptor than the previous two steps.
- kind: RequestBuilder
name: requestBuilderTelegram
template: |
{{$msg := or .requests.DEFAULT.JSONBody.message .requests.DEFAULT.JSONBody.channel_post}}
method: POST
# Please replace it with the url of your bot
url: https://api.telegram.org/bot0123456789:AABBCCDDEEFFGG-5sijosfjfsjiWVdi743/sendVoice
formData:
chat_id:
value: {{$msg.chat.id}}
reply_to_message_id:
value: {{$msg.reply_to_message.message_id}}
voice:
fileName: "tg.ogg"
value: !!binary "{{.responses.polly.Body | b64enc}}"
- name: proxyTelegram
kind: Proxy
pools:
- servers:
- url: https://api.telegram.org
Finally, we also need a ReponseBuilder to create a Response for the original Request, which is very simple and we will omit it here. Once all the Filters have been configured, we can orchestrate them with the YAML below. Note that since the entire process involves multiple Requests and Responses, we are using namespaces. Most Filters can only use Requests and Responses in their own namespace, but RequestBuilder and ResponseBuilder can access all Requests and Responses, see later for details.
flow:
# we put the ResponseBuilder at the top because Telegram requires us to return a response for
# every Request, but we only process some of the requests. If we put it at the end, the
# requests we don't process will end the process early and no Response will be returned.
- filter: responseBuilder
# translation
- filter: requestBuilderTranslate
namespace: translate
- filter: requestAdaptorTranslate
namespace: translate
- filter: proxyTranslate
namespace: translate
# text to speech
- filter: requestBuilderPolly
namespace: polly
- filter: requestAdaptorPolly
namespace: polly
- filter: proxyPolly
namespace: polly
# send the voice message to Telegram
- filter: requestBuilderTelegram
namespace: tg
- filter: proxyTelegram
namespace: tg
Save the complete configuration (you can find it from the appendix of this article) as telegram-pipeline.yaml and execute:
$ egctl object create -f telegram-pipeline.yaml
we will have the pipeline created.
But only the pipeline is not enough, we also need to create an HTTPServer and have it forward the Telegram request to the above pipeline, note that the external address of this pipeline must be the address of the Telegram WebHook we created earlier.
$ echo '
kind: HTTPServer
name: server-demo
port: 10080
keepAlive: true
https: false
rules:
- paths:
- pathPrefix: /telegram
backend: telegram-pipeline' | egctl object create
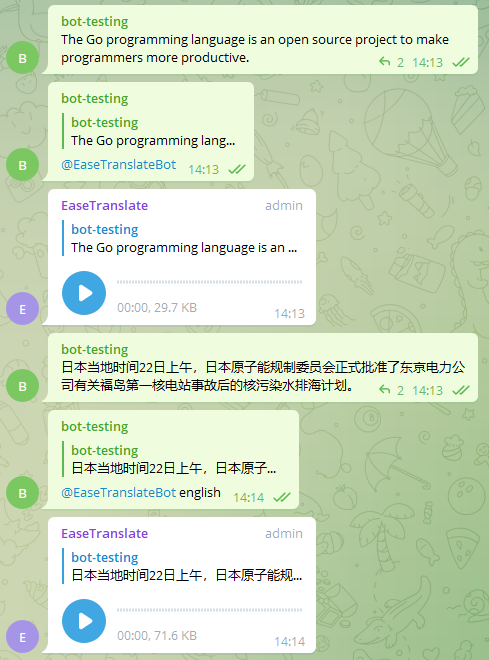
After that, send a message in a way similar to the following figure to see the result of the bot’s execution. The voice message in the figure is sent by the bot, and the other messages are sent by us.
Improvements
To achieve the three goals we have mentioned above: multi-protocol support, decoupling of control logic and business logic, and powerful and easy-to-use API orchestration, we have made the following improvements.
First, we’ve defined the functionality of the three core objects Context, Filter, and Pipeline:
Context is a data container, requests and responses are the data in it, data can be protocol dependent, but the container must be protocol independent;
Filter processes data, can be either protocol-dependent or protocol-independent, but must focus on business logic;
Pipeline orchestrates filters and focuses on control logic, which must be protocol-dependent.
Second, the resilience filters (Retryer, CircuitBreaker, and TimeLimiter) are deleted, and resilience policies are defined on the pipeline. A filter can implement the Resiliencer interface to support resilience, and if it does, Pipeline will inject resilience policies into it when creating the filter.
Third, in v1.x, each Context can only store one request and one response. In order to support complex API orchestration, the Context in v2.0 is divided into multiple namespaces, and each namespace can store one request and one response. At the same time, when defining a Pipeline, users can specify a namespace for each filter, and this filter uses the request and response in the namespace by default. And we added two new filters, RequestBuilder and ResponseBuilder, to break the boundary of the namespaces, both Filters can access all data in the Context, and then save the newly generated request or response to the specified namespace, as shown below(DEFAULT & slack are namespaces).

The above improvements not only solve the problems of v1.x, but also greatly enhance the flexibility of traffic orchestration, giving Easegress the ability to process business logic like a workflow engine. This provides another way to handle business logic intrusions.
Pipeline DSL
To reflect improvements in design and implementation, Pipeline DSL has also been fine-tuned and optimized.
1. Pipeline
Protocol independent pipeline
name: demo-pipeline
kind: Pipeline # always Pipeline, no more HTTPPipeline and etc.
2. Resilience policies
Resilience policies are now defined on the pipeline:
filters:
- name: proxy
kind: Proxy
pools:
- servers:
...
timeout: 500ms
retryPolicy: retry3Times # use a retry policy
circuitBreakerPolicy: circuitBreakAfter10Failure # use a circuit breaker policy
...
resilience: # added in v2.0, define resilience policies
- name: retry3Times
kind: RetryPolicy
maxAttempts: 3
...
- name: circuitBreakAfter10Failure
kind: CircuitBreakerPolicy
...
3. User Data
These data can be referenced either by code in the filter or in the template of RequestBuilder / ResponseBuilder using a form such as .data.PIPELINE.english.voice.
filters:
- kind: Proxy
name: proxy
...
data:
chinese:
code: zh
voice: Zhiyu
english:
code: en
voice: Joanna
4. Namespace
We can use namespace to specify the namespace that a filter belongs to, the default namespace is DEFAULT.
flow:
- filter: validator
- filter: buildRssRequest
namespace: rss # added in v2.0
5. Built-in Filter END
We can use the END filter to terminate the pipeline, END is a built-in filter, you don’t need to define it.
flow:
- filter: validator
jumpIf:
invalid: buildFailureResponse
- filter: proxy
- filter: END # terminate here
- filter: buildFailureResponse
6. Alias
Filter mockRequest appears twice in the below pipeline, by using an alias, we know it will jump to the second appearance if the validation of validator fails.
flow:
- filter: validator
jumpIf:
invalid: mockRequestForProxy2 # jump via alias
- filter: mockRequest
- filter: proxy1
- filter: END
- filter: mockRequest
alias: mockRequestForProxy2 # assign an alias to the filter
- filter: proxy2
7. RequestBuilder & ResponseBuilder
RequestBuilder and ResponseBuilder can create a reference to an existing request or response in the target namespace, or use a template to generate a brand new request or response. The templates are based on the text/template of the standard Go library, with extra helper functions from sprig.
name: buildSlackRequest
kind: HTTPRequestBuilder
sourceNamespace: rss # sourceNamespace & template cannot be used together
template: |
method: POST
url: /services/TXXXXXXX/BXXXXXXXXX/xyxyxyxyxyxyxyxyxyxyxy
body: |
{
"text": "Recent Posts - {{.responses.rss.JSONBody.title}}",
"blocks": [{
"type": "section",
"text": {
"type": "plain_text",
"text": "Recent Posts - {{.responses.rss.JSONBody.title}}"
}
}, {
"type": "section",
"text": {
"type": "mrkdwn",
"text": "{{range $index, $item := .responses.rss.JSONBody.items}}• <{{$item.url}}|{{$item.title}}>\n{{end}}"
}}]
}
Migrate v1.x Filters to v2.0
Since v2.0 has many improvements, it is not fully compatible with v1.x, and filters developed for v1.x needs some modifications to work with v2.0, please refer to this guide for detailed steps.
Appendix: RSS Pipeline
name: telegram-pipeline
kind: Pipeline
flow:
# we put the ResponseBuilder at the top because Telegram requires us to return a response for
# every Request, but we only process some of the requests. If we put it at the end, the
# requests we don't process will end the process early and no Response will be returned.
- filter: responseBuilder
# translation
- filter: requestBuilderTranslate
namespace: translate
- filter: requestAdaptorTranslate
namespace: translate
- filter: proxyTranslate
namespace: translate
# text to speech
- filter: requestBuilderPolly
namespace: polly
- filter: requestAdaptorPolly
namespace: polly
- filter: proxyPolly
namespace: polly
# send the voice message to Telegram
- filter: requestBuilderTelegram
namespace: tg
- filter: proxyTelegram
namespace: tg
data:
chinese:
code: zh
voice: Zhiyu
english:
code: en
voice: Joanna
french:
code: fr
voice: Léa
japanese:
code: ja
voice: Mizuki
korean:
code: ko
voice: Seoyeon
german:
code: de
voice: Vicki
spanish:
code: es
voice: Lucia
arabic:
code: ar
voice: Zeina
dutch:
code: nl
voice: Lotte
italian:
code: it
voice: Carla
polish:
code: pl
voice: Ewa
filters:
- kind: RequestBuilder
name: requestBuilderTranslate
template: |
{{$msg := or .requests.DEFAULT.JSONBody.message .requests.DEFAULT.JSONBody.channel_post}}
{{if contains "@easetranslatebot" (lower $msg.text)}}
{{$lang := or (trim (replace "@easetranslatebot" "" (lower $msg.text))) "chinese"}}
{{$lang = index .data.PIPELINE (lower $lang)}}
method: POST
url: https://translate.us-east-2.amazonaws.com/TranslateText
headers:
"Content-Type": ["application/x-amz-json-1.1"]
"X-Amz-Target": ["AWSShineFrontendService_20170701.TranslateText"]
body: |
{
"SourceLanguageCode": "auto",
"TargetLanguageCode": "{{$lang.code}}",
"Text": "{{$msg.reply_to_message.text | jsonEscape}}"
}
{{end}}
- name: requestAdaptorTranslate
kind: RequestAdaptor
sign:
apiProvider: aws4
# Please use your own access key & secret
accessKeyId: AKXXXXXXXXXXXXXXXXXX
accessKeySecret: XYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY
scopes: ["us-east-2", "translate"]
- name: proxyTranslate
kind: Proxy
pools:
- servers:
- url: https://translate.us-east-2.amazonaws.com
- kind: RequestBuilder
name: requestBuilderPolly
template: |
{{$msg := or .requests.DEFAULT.JSONBody.message .requests.DEFAULT.JSONBody.channel_post}}
{{$lang := or (trim (replace "@easetranslatebot" "" (lower $msg.text))) "chinese"}}
{{$lang = index .data.PIPELINE (lower $lang)}}
method: POST
url: https://polly.us-east-2.amazonaws.com/v1/speech
headers:
"Content-Type": ["application/json"]
body: |
{
"Engine": "standard",
"OutputFormat": "ogg_vorbis",
"Text": "{{.responses.translate.JSONBody.TranslatedText | jsonEscape}}",
"VoiceId": "{{$lang.voice}}"
}
- name: requestAdaptorPolly
kind: RequestAdaptor
sign:
apiProvider: aws4
# Please use your own access key & secret
accessKeyId: AKXXXXXXXXXXXXXXXXXX
accessKeySecret: XYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY
scopes: ["us-east-2", "polly"]
- name: proxyPolly
kind: Proxy
pools:
- servers:
- url: https://polly.us-east-2.amazonaws.com
- kind: RequestBuilder
name: requestBuilderTelegram
template: |
{{$msg := or .requests.DEFAULT.JSONBody.message .requests.DEFAULT.JSONBody.channel_post}}
method: POST
# Please replace it with the url of your bot
url: https://api.telegram.org/bot0123456789:AABBCCDDEEFFGG-5sijosfjfsjiWVdi743/sendVoice
formData:
chat_id:
value: {{$msg.chat.id}}
reply_to_message_id:
value: {{$msg.reply_to_message.message_id}}
voice:
fileName: "tg.ogg"
value: !!binary "{{.responses.polly.Body | b64enc}}"
- name: proxyTelegram
kind: Proxy
pools:
- servers:
- url: https://api.telegram.org
- kind: ResponseBuilder
name: responseBuilder
template: |
statusCode: 200
``